Social Network Data Scraping from BlackBoard
Social Network Data Scraping from BlackBoard
For those who are interested in extracting interaction data from BlackBoard system
Basic understand of python programming including Flow Control, Built-in Function, and indexing.
If you are not sure, please read the last section.
After reading the description, the paticipants of this content can
1) make a pseudo code to develop scraping code
2) recognize the underlying logic of example code
3) adjust the example code to apply their Blackbord course
Text-based asynchronous online discussion has been highlighted among online researchers as a way of fostering the critical thinking of university-level students. Garrison et al's (2000) Community of Inquiry (CoI) framework produced the theoretical support on the effectiveness of asynchronous text-based discussion. The framework's emphasis on the inseperability of individual and community has epistemological affinity with Social Network Analysis (SNA); however, the integration of SNA into CoI practice and research is limited. According to my systematic review, 15 peer-reviwed CoI articles utiilized SNA.
(see: https://coi.athabascau.ca/coi-model/)
I guessed that the reasons of this passiveness are:
1) The exploratory level of this integration that produces theoretical and methodological uncertainty and hesitance.
2) The SNA tools that are not affordable for researchers or practitioners.
This content will contribute to handling the second issue by demonstrating the way of extracting data for SNA from BlackBoard.
Before going to the main content, the participants need to be familiar with the basic concept of SNA by reading https://www.merlot.org/merlot/viewMaterial.htm?id=353381. Reading Part 1 to Part 5 is enough. Skip the explanation of Netdraw.
Moreover, the participants need to install python 3 and jupyter notebook. Installing anaconda (https://www.anaconda.com/products/individual#Downloads) is a solution. This setting process will differ depending on each computing environment. StackOverflow (https://stackoverflow.com/) is strikingly helpful in solving problems you will met.
Basic understanding of python programming system is required, but this course hopes to share the replicable python code with the explanation of logic (pseudo-code)
Web scraping is the process of using bots to extract content and data from a website.
(see: https://www.imperva.com/learn/application-security/web-scraping-attack/)
The characteristic of a website influences the way of scraping. A static website (such as an old website) is easy to be scrapped, but a dynamic website, which can change the part of content while remaining other as the same, is hard. The example of dynamic website is SNS like Facebook/Meta, twitter, and instragram. Blackboard is close to a static website. However, the python code I developed uses the python library that is to scrap a dynamic website. I will explain why below.
! Difference between libraries for scraping a static website and for a dynamic website?
Actually, there is no clear boundary between them. However, one analogy to explain how to scrap a dynamic website is that a bot needs to act like a human user to gather data from a dynamic website. Your bot can scroll a page down and click a button to pop up the additional information. A static scraping bot can only read the surface of data whereas a dynamic scraping bot can dig into the land to reach the hidden data.
What's the expense? a static scraping bot is resistant to networking error, but a dynamic scraping bot is not.
* This issue is out of topic, but you will meet this issue when you apply the given code to your own data.
Selenium is the bot to control programs in a remote. By its virtue, this bot is utilized for dynamic scraping.
Go to the download page (https://pypi.org/project/selenium/) and find a specific driver considering your web browser. Please be careful to remember the specific directory where you download the driver.
Making pseudo-code is a practice to make your logic of problem-solving clear and efficient. As the principle of Computer Science states, computer science is not about coding but a strategic approach to problem-solving throught algorithmatic thinking. The detailed description is here (https://users.csc.calpoly.edu/~jdalbey/SWE/pdl_std.html).
However, you don't need to follow a strict way of writing pseudocode. (actually I also didn't) Just try to understand and follow the below process step by step.
I am not sure about my exploration is the same to all BlackBoard system, but what I figure out are:
1) The general user can not know the logic behind the URL structure of courses, discussion boards, and postings. Each URL shares a specific structure, but the number assigned to the URL seems arbitrary or seems to follow the behind the logic.
2) Each discussion consists of postings. Each posting consists of main content and replies from others.
3) On the posting page, a user can read a) the name of the posting writer, b) the date of the posting, c) the title of the posting, d) the content of the posting, e) the name of the reply writer, f) the date of the reply, g) the content of reply.
* "a user can read" means your selenium bot can read the content and run the function.
4) The relationship between replies seems hierarchical. When someone puts a reply on another reply, this new reply starts from the right-below side of the previous one. It is a kind of indentation.
5) A user can move to the next posting by clicking to 'next button' and see the total number of postings

Can you see the '>' icon right to the "Thread 1 of 30"?
To gather data:
1) The bot needs to know where she should go to gather the data:
1-1) URL information seems not to be organized by the order of posting.
1-2) However, the bot can read "how many times she should click the 'next' button" and can click the next button.
2) The bot needs to know what data she should read and save:
2-1) Basically, the data for SNA is the interaction between users. We can treat 'who gives comment(reply) on whom' as the unit of interaction.
2-2) Additionaly, I am interested in a) the date of the posting and reply, c) the title of the posting, d) the hierarchical relationship between replies and the posting and reply.
2-3) he hierarchical relationship between replies and the posting and reply is crucial to know 'who gives a comment(reply) on whom'
3) The bot needs to read the data
3-1) The only problem is that the bot cannot directly read the hiearchical relationship.
3-2) However, the bot can read the information of locations.
3-2-1) As explored before, "When someone puts a reply on another reply, this new reply starts from the right-below side of the previous one. It is a kind of indentation."
Example:
| Original Posting | |||
| Reply 1 | |||
| Reply 2 | |||
| Reply 3 | |||
| Reply 4 | |||
| Reply 5 | |||
| Reply 6 | |||
| Reply 7 | |||
3-2-2) The substraction between X-axis of replies (or posting) gives the information of hierarchical relationship.
3-2-2-1) The original posting always starts from 164 of X-axis
3-2-2-2) The locational (x-axis) difference between original posting (reply) and a reply to this posting(or reply)is almost 18 (19 in a few times).
* I will use 'parent reply' and chidren reply' to help understaing.
3-3) The X-axis of reply substracted by 164 and then divided by 18 refers the hierarchy
3-4) 18 or 19 of locational difference between replies refers to the parent-child relationship (who gives a comment on whom)
1) Library Loading
2) Selenium Driver Loading
* I used chrome web brower.
After you run this code, you can see the new and blank web browser that can be controlled by Selenium
3) Moving to the first posting of the discussion
You can customize the moving to the first posting of the discussion by using selenium, but I want to reduce the steps that you need to understand.
Please manually go to the BlackBoard, log in, and click the first posting of the target discussion.
If you reach this kind of page, you are ready!
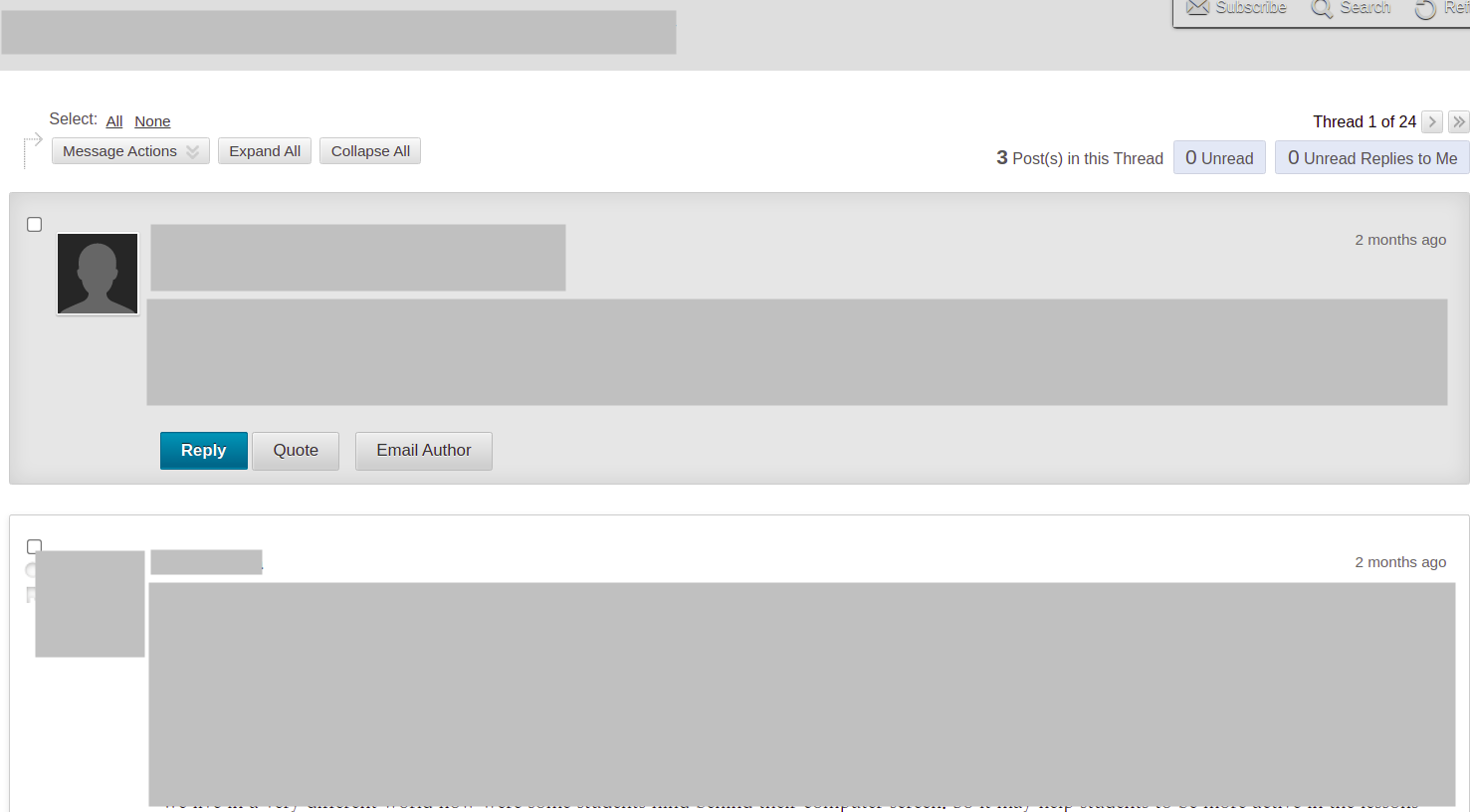
4) Making the blank lists that each kind of information will be stored
5) Extracting the target data
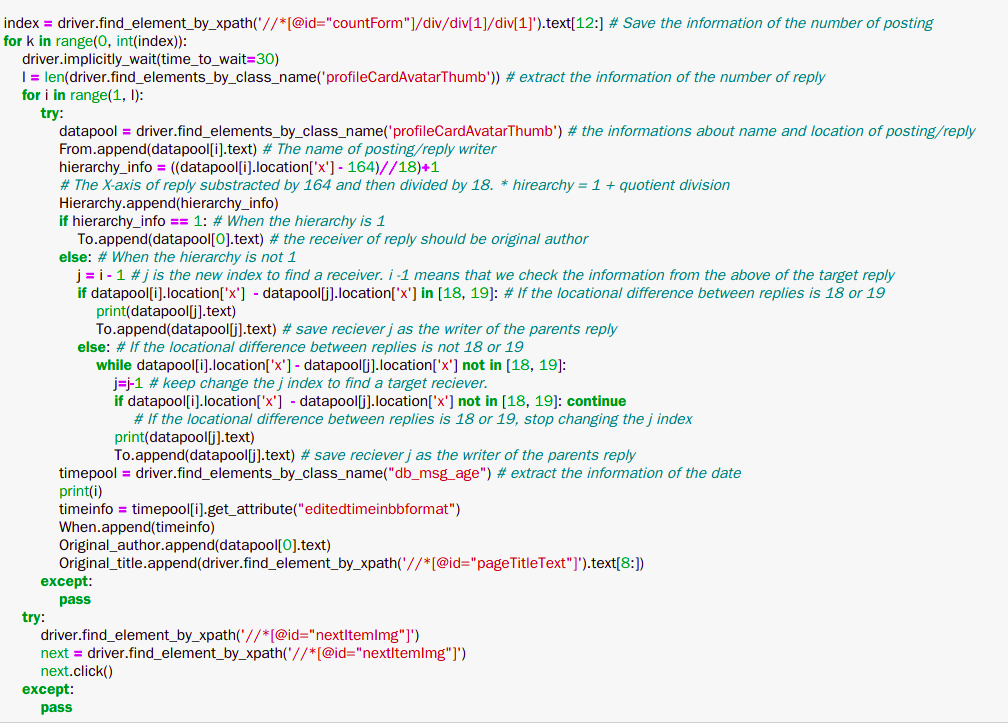
6) Organizing the data

Take a deep breath. Understaning the above code is hard for those who are not famliar with python programming.
When you feel frustrated after reading the code, please do not give up. The below source will be helpful.
How to locate selenium (Xpah, css selector, class name): https://www.softwaretestingmaterial.com/how-to-locate-element-by-class-name-locator/
Driver wait: https://www.browserstack.com/guide/wait-commands-in-selenium-webdriver
Flow Control
Python - For loop: https://www.w3schools.com/python/python_for_loops.asp
Python - While loop: https://www.w3schools.com/python/python_while_loops.asp
Python - if... else... : https://www.w3schools.com/python/python_conditions.asp
Python - try... except... : https://www.w3schools.com/python/python_try_except.asp
Built-in fuction
Python - append: https://www.w3schools.com/python/ref_list_append.asp
Indexing
https://realpython.com/lessons/indexing-and-slicing/